
Teradata offers a relational database management system (RDBMS) suitable for large-scale data warehousing and analytics. In Teradata’s platform, a table operator is a function that can be called using structured query language (SQL). It accepts a table as input, performs some operations on it, and produces another table as output. Script Table Operator (STO) is part of Teradata’s focus to provide an open and connected architecture, where data scientists and data engineers can define custom table operators using a language of their choice (such as Python and R) and run that operator within the platform at scale using Teradata's massively parallel processing (MPP) architecture.
With STO, Teradata’s existing capabilities can be greatly enhanced with new functionalities previously not available natively in SQL.
In this step-by-step guide, learn how STO can be leveraged to perform optical character recognition (OCR) on images and PDFs stored in Teradata’s platform in a table, enhancing Teradata’s capabilities to perform OCR.
Teradata’s platform
Teradata offers the most complete cloud analytics and data platform for AI. The platform is a popular choice as a data warehouse for large-scale businesses to store and analyze data.
Teradata supports analytics at scale thanks to its MPP, shared-nothing distributed architecture. The computing engine consists of several Access Module Processors (AMPs). Any data stored in a table gets distributed across AMPs through a hashing scheme. Any operator executed on the table using SQL runs in parallel on all AMPs on table rows assigned to the respective AMPs. The results from distributed executions of the function on AMPs are then synthesized and stored in an output table, fulfilling a MapReduce (MR) scheme of computing.
The native SQLMR functions have a rich set of data processing, model training, and model scoring capabilities. Due to the availability of these functions, data doesn’t have to be moved to any external environment for analytics. Any additional functions of interest can be moved to the data, thanks to the STO, as we’ll demonstrate. This avoids costly movement of data between environments, providing savings of time and money, and utilizes the power of MPP. Keeping data within Teradata’s platform may also be desirable for customers who have strict governance requirements around data.
What is a Script Table Operator (STO)?
STO injects new functionality into existing SQLMR capabilities. Typically, users can write their own scripts in Python/R and use them in SQL scripts, just like native SQLMR functions. Our focus is on developing such an STO with Python to perform OCR on images stored in Teradata. To provide user-defined STO capabilities with Python, Teradata maintains a Python environment on every AMP. A significant number of Python libraries are preinstalled in the environment and ready to use. Additional required libraries can be installed with the help of a database administrator (DBA).
An STO is written assuming that, when called, Teradata’s platform passes tabular data to the operator in the standard input stream (stdin) in a comma-separated format, and that Teradata receives tabular output from the operator in a similar fashion in the standard output stream (stdout). The operator script reads the table from stdin, performs processing on it per required logic, and writes the output table to the stdout. This happens in a row-by-row fashion. The values in individual rows and columns from stdin are read as strings possibly encoded in Unicode text format. These values can then be converted to appropriate data types within the operator code for processing.
The maximum allowed memory for an STO is 3.5 GB. An appropriate upper limit can be set per the requirements with the support of a DBA.
What is EasyOCR?
EasyOCR is a lightweight open-source Python library, developed and maintained by Jaided AI, that uses deep learning and computer vision techniques to recognize written texts in images. EasyOCR caters to both handwritten and typed text and provides support for multiple languages. Our focus is recognizing text written in the English language only.
EasyOCR uses deep learning models under the hood. It uses different models for different languages and can automatically download these models from the internet on the fly. In our case, the Teradata system would not have an internet connection. However, EasyOCR can also be used in offline mode, in which models required can be downloaded beforehand in a directory whose path can be provided to EasyOCR as model directory.
Due to EasyOCR being lightweight and allowing offline mode of operation, it’s a good choice to be used in STO where computational limits may be tight. It’s not in the STO environment by default, but it can be installed.
A high-level architecture and the OCR logic with STO is shown below.
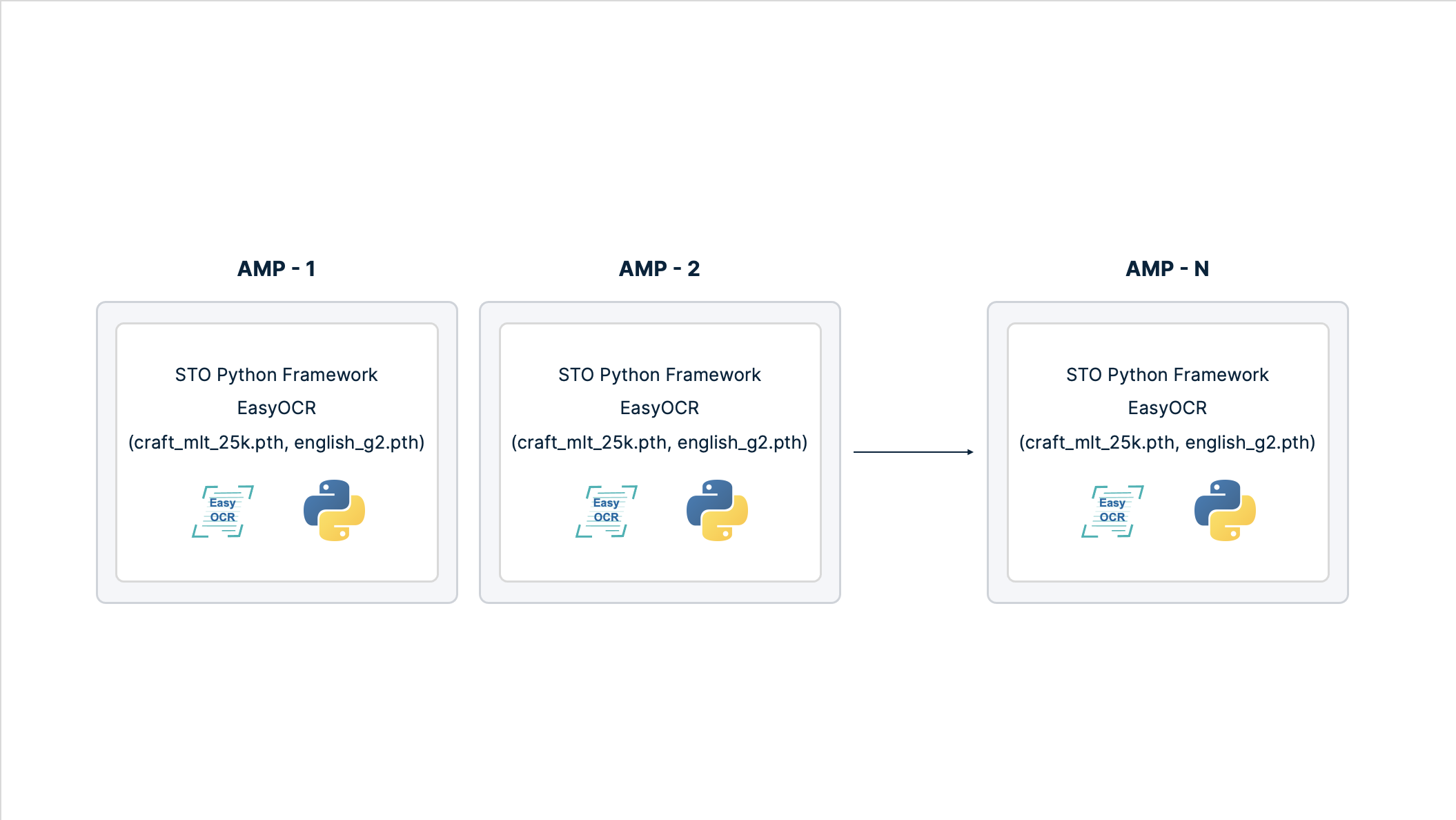
Figure 1: Installation of EasyOCR and the underlying deep learning models in the STO Python environment on each AMP.
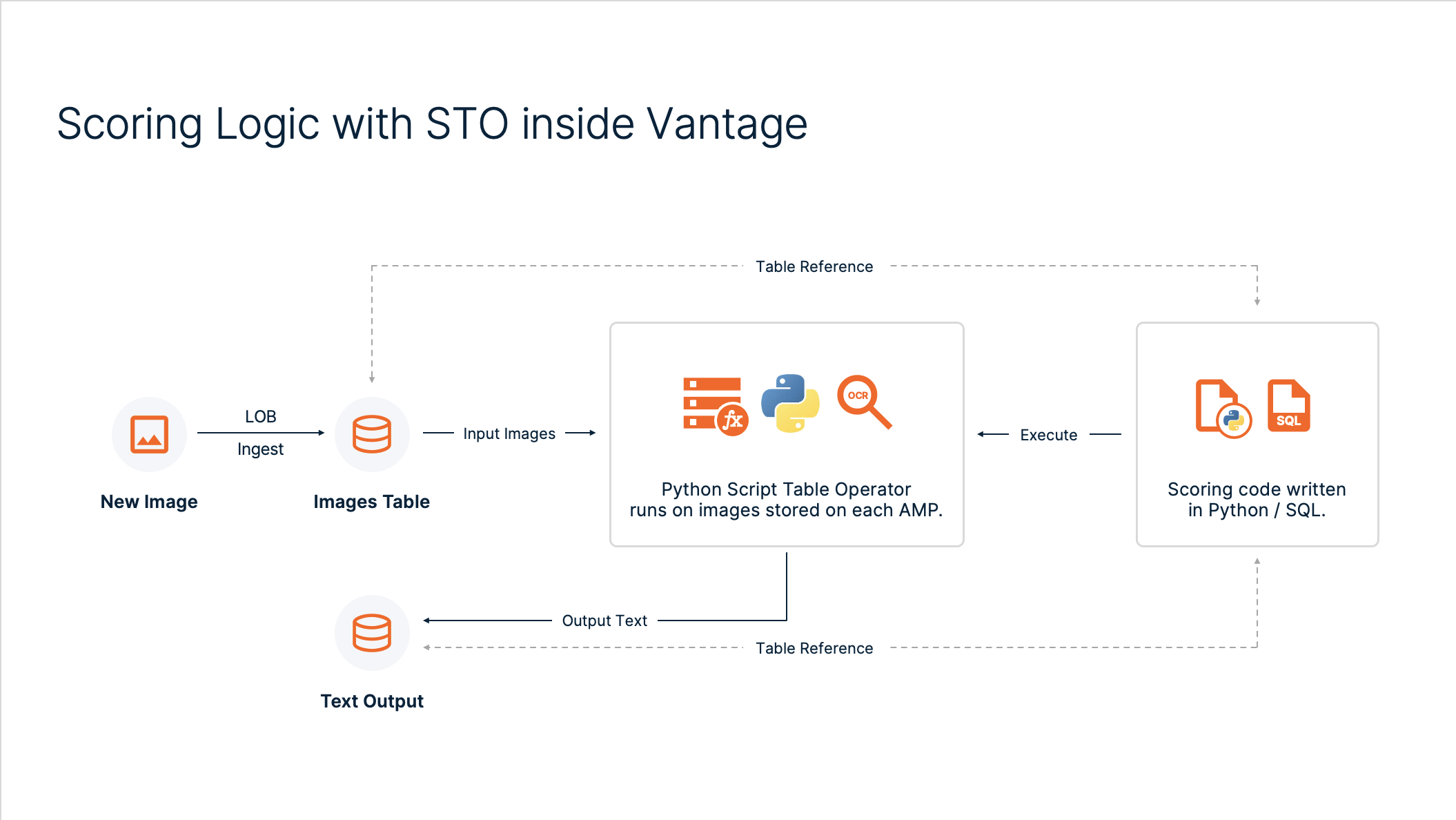
Figure 2: OCR logic with STO.
Code walkthrough
The code was developed in a Jupyter environment on the client side with Python version 3.12 and teradataml version 20.0.0.5. The STO environment in Teradata’s system had Python version 3.8 and EasyOCR version 1.7.2 installed.
1. Import Python libraries on the client side
The following libraries need to be imported into the Python environment on the client side.
import getpass
import glob
import cv2
from PIL import Image
import io
import pandas as pd
from teradataml import (
DataFrame,
create_context,
Script,
execute_sql,
OrderedDict,
INTEGER,
CLOB,
copy_to_sql,
)
import pickle
import base64
The library named “teradataml” provides a Python interface for Teradata’s system. It allows us to use the STO capabilities. It also provides a Teradata DataFrame, which points to a view/table in database and acts very much like a pandas DataFrame without pulling data out. All updates/modifications to this DataFrame are pushed down to Teradata’s system as SQL commands.
2. Connect to Teradata’s system
Next, we create a connection with the Teradata instance.
user = "<user_name>"
password = getpass.getpass()
host = "<host_name>"
eng = create_context(host=host, username=user, password=password)
execute_sql(f"""Set session SEARCHUIFDBPATH = <user_name>;""")
3. Loading images to Teradata
Before STO can be applied, images need to be stored in a table in Teradata. We’ll store images as character large object (CLOB) data structure in a table with just two columns: ID and IMAGE. A similar approach can be extended to PDFs in which individual PDF pages can be treated as images. These pages represented as images can be stored in tables as CLOBs. However, we need the following helper functions to process images before storing them as CLOBs.
def image_to_pickle(image_path):
image = Image.open(image_path)
image_bytes = io.BytesIO()
image.save(image_bytes, format=image.format)
image_bytes = image_bytes.getvalue()
pickled_image = pickle.dumps(image_bytes)
return pickled_image
def pickle_to_string(obj):
pickled_bytes = pickle.dumps(obj)
base64_bytes = base64.b64encode(pickled_bytes)
string_representation = base64_bytes.decode("ascii")
return string_representation
The function “image_to_pickle” reads the image from a given path and returns the image in pickle format. The function “pickle_to_string” encodes the image in pickle format to string representation using the “base64” library.
This encoding is necessary for an image to be passed to the STO. Without it, we’ll get encoding errors while reading from the stdin inside the operator script. Note that we need to do the reverse process in the operator script to bring the image back to a usable format.
Images are then loaded from the local file system and placed in a pandas DataFrame:
imgs = glob.glob("<path_to_images_directory>")
Data = []
for i in range(len(imgs)):
pkl = image_to_pickle(imgs[i])
str_pkl = pickle_to_string(pkl)
lst = [i, str_pkl]
Data.append(lst)
DF = pd.DataFrame(Data, columns=["ID", "IMAGE"])
The DataFrame can then be stored as a table in Teradata’s system using the teradataml package. Images are stored as CLOBs.
copy_to_sql(
df=DF,
table_name="OCR_Images",
schema_name=user,
if_exists="replace",
primary_index="ID",
types={"ID": INTEGER, "IMAGE": CLOB},
)
Now, we can create a teradataml DataFrame of the table “OCR_Images”.
DF = DataFrame("""OCR_Images""")
4. The STO
The content of the script file named “ocr_sto_easy” is given below:
%%writefile ocr_sto_easy.py
import sys
import os
# Disable output to stdout
def blockPrint():
sys.stdout = open(os.devnull, "w")
# Restore output to stdout
def enablePrint():
sys.stdout = sys.__stdout__
blockPrint()
from PIL import Image
import base64
import pickle
import io
import easyocr
import csv
def pickle_to_image(pickled_image):
unpickled_image = pickle.loads(pickled_image)
image = Image.open(io.BytesIO(unpickled_image))
return image
def string_to_pickle(string_representation):
base64_bytes = string_representation.encode("ascii")
pickled_bytes = base64.b64decode(base64_bytes)
obj = pickle.loads(pickled_bytes)
return obj
DELIMITER = "\t"
# Lambda functions to convert the data types appropriately
sciStrToInt = lambda x: int(float("".join(x.split())))
sciStr = lambda x: x
csv.field_size_limit(sys.maxsize)
csv_reader = csv.reader(sys.stdin, delimiter=DELIMITER)
reader = easyocr.Reader(["en"], model_storage_directory="./<user>/")
enablePrint()
for row in csv_reader:
i = sciStrToInt(row[0])
img = sciStr(row[1])
img = string_to_pickle(img)
img = pickle_to_image(img)
ext_txt = reader.readtext(img, canvas_size=1500, detail=0)
separator = ", "
ext_txt = separator.join(ext_txt)
ext_txt = ext_txt.replace("\t", " ")
ext_txt = ext_txt.replace("\n", " ")
print(i, ext_txt, sep=DELIMITER)
Apart from the usual imports, there are a few important things to note. The two functions “disablePrint” and “enablePrint” respectively disable and enable output to the stdout. We disable output to stdout to make sure no libraries or functions write anything to the output stream that could interfere with the actual output of the operator. The two lambda functions simply cast input column values of a row to appropriate data types (i.e., “ID” to Integer and “IMAGE” to String). The functions “string_to_pickle”, and “pickle_to_image” convert an image back from CLOB to image format for OCR.
This script is executed on every AMP on all the rows stored on that AMP. We read the input table of images row by row using the “csv_reader,” convert the image in the row to the appropriate image format, and use EasyOCR to get the text out. In this instance, we keep the “detail” parameter to 0 to only take the text out without coordinate information. Also, we keep the “canvas_size” to a relatively lower value of 1,500 to keep the memory requirements of the STO lower. This is so images can be converted without violating the memory limits set for the STO. We remove the special characters for newline and tab (‘\n’ and ‘\t’) from the text before writing to stdout, as these special characters have special meanings in STO and will mess up the output of the STO. It’s important to keep the original image ID in every row of the output table to keep referential integrity so that images can be properly mapped to their extracted texts. The row-by-row output from this operator can later be consumed into a Teradata table.
As mentioned earlier, EasyOCR downloads models from the internet to do OCR, and the given Teradata instance may not have an active internet connection. So, we use EasyOCR in offline mode. For our task, we need the models “craft-mlt-25k.pth” and “english-g2.pth” downloaded on a local machine and then uploaded to the STO’s Python environment (shown below). The model directory of the EasyOCR is set to the current user’s home directory in the STO environment.
We then define the script object using this script file as:
sto = Script(
data=DF[["ID", "IMAGE"]],
data_hash_column="ID",
script_name="ocr_sto_easy.py",
files_local_path="./",
script_command=f"tdpython3 ./<user>/ocr_sto_easy.py",
delimiter="\t",
returns=OrderedDict([("ID", INTEGER()), ("OCR_TEXT", CLOB())]),
)
Note that DF here is a teradataml DataFrame and not a pandas DataFrame. As mentioned earlier, Teradata’s DataFrame object is a handle to a table/view in Teradata’s system. It doesn’t pull contents of the table out of Teradata’s system unless requested. The parameters of the script object are:
- The input table’s DataFrame
- The hash column, which determines data distribution between AMPs
- The name of the script file
- The local directory path at which the file is stored
- The shell command that will be executed on each AMP once the script file has been uploaded on each AMP
- The delimiter character used to separate the individual values of each column in each row of the table to be received on the stdin
- The schema of the output table
The script file is then installed on each AMP using the “install_file” method:
sto.install_file(
file_identifier="ocr_sto_easy", file_name="ocr_sto_easy.py", is_binary=False
)
sto.remove_file(file_identifier="ocr_sto_easy", force_remove=False)
sto.install_file(file_identifier='craft_mlt_25k', file_name='craft_mlt_25k.pth', is_binary=True)
sto.install_file(file_identifier='english_g2', file_name='english_g2.pth', is_binary=True)
Note the change in the “is_binary” parameter (from False to True) to the “install_file” method compared to the previous call to “install_file” for the script. Models should be passed as binaries and scripts as nonbinaries. The “install_file” method uploads the file to the database user’s home directory in STO environment.
The script can then be executed and the output DataFrame saved as a table in Teradata’s system. Again, the output DataFrame here is a Teradata DataFrame pointing to some volatile table in the database.
df = sto.execute_script()
copy_to_sql(
df=df,
table_name="Processed_Images",
schema_name=user,
if_exists="replace",
primary_index="ID",
types={"ID": INTEGER, "OCR_TEXT": CLOB},
)
The table will look something like this.

Note that the process of extracting text is very basic here. One usually needs to do some amount of image processing to enhance images before giving them to the OCR tool so that text can be properly extracted without much loss. The OpenCV Python library can typically be used here in the STO. However, this topic is beyond our scope here.
5. Extract information from text
Once the texts have been extracted from images and saved in a table, these can be further processed for specific business needs. For example, if the images being considered contain purchase receipts from various stores in Australia, the Australian Business Number (ABN) and the Australia Company Number (ACN) can be extracted from the text and stored as separate features. Here’s how this can be done with another Script Table Operator that performs regex matching on the extracted text.
%%writefile extract_info.py
import sys
import os
# Disable
def blockPrint():
sys.stdout = open(os.devnull, "w")
# Restore
def enablePrint():
sys.stdout = sys.__stdout__
blockPrint()
import csv
import re
DELIMITER = "\t"
# Lambda functions to convert the data types appropriately
sciStrToInt = lambda x: int(float("".join(x.split())))
sciStr = lambda x: x
enablePrint()
csv.field_size_limit(sys.maxsize)
csv_reader = csv.reader(sys.stdin, delimiter=DELIMITER)
for row in csv_reader:
i = sciStrToInt(row[0])
text = sciStr(row[1])
regex_abn = r"ABN:?\s*(\d{1,2}(?:\s*\d{1,3}){0,10})"
abn = ""
match = re.search(regex_abn, text)
if match:
abn = match.group(1)
abn = re.sub(r"\s+", "", abn)
regex_acn = r"ACN:?\s*(\d{1,3}(?:\s*\d{1,3}){0,2})"
acn = ""
match = re.search(regex_acn, text)
if match:
acn = match.group(1)
acn = re.sub(r"\s+", "", acn)
print(i, abn, acn, sep=DELIMITER)
DF = DataFrame("""Processed_Images""")
sto = Script(
data=DF[["ID", "OCR_TEXT"]],
data_hash_column="ID",
script_name="extract_info.py",
files_local_path="./",
script_command=f"tdpython3 ./demo_user/extract_info.py",
delimiter="\t",
returns=OrderedDict(
[("ID", INTEGER()), ("ABN", VARCHAR(20)), ("ACN", VARCHAR(20))]
),
)
sto.install_file(
file_identifier="extract_info", file_name="extract_info.py", is_binary=False
)
df = sto.execute_script()
copy_to_sql(
df=df,
table_name="Extracted_Features",
schema_name=user,
if_exists="replace",
primary_index="ID",
types={"ID": INTEGER, "ABN": VARCHAR(20), "ACN": VARCHAR(20)},
)
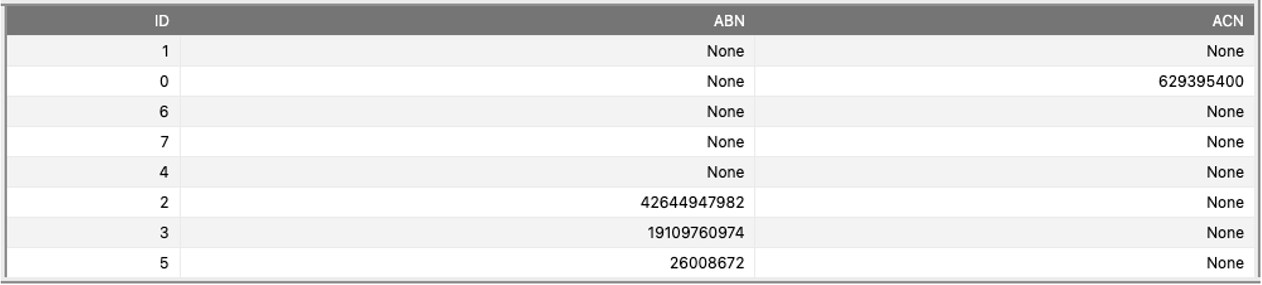
The extracted ABN and ACN will be saved in the table “Extracted_Features” if found in the corresponding text.
The output looks like the following in our case:
Conclusion and future work
While Teradata’s system may not have an in-built function to do OCR on images, its functionality can be enhanced with STO to do this. Use of STO is particularly advantageous when large datasets need to be processed in parallel faster than sequential data processing that may lead to bottlenecks.
Script Table Operator technology is enhanced with Teradata’s new Open Analytics Framework (OpenAF), which provides Docker-based environments, gives much higher memory limits, and comes with graphics processing unit (GPU) support to run large deep learning and language models. The code here can be easily modified to work with OpenAF, and it would be interesting to try it. Learn more about OpenAF and other Teradata technologies.